
Artificial General Intelligence (AGI) isn’t just a sci-fi concept anymore—it’s becoming a real possibility. AGI refers to systems with intelligence equal to or beyond human-level performance across a wide range of tasks, not just narrow capabilities like chatbots or image recognition. The promise is huge: solving complex problems, accelerating research, transforming industries. But with great power comes equally great risk.
That’s why Google DeepMind recently published a paper titled “An Approach to Technical AGI Safety and Security,” outlining how we might build AGI safely. Instead of waiting for definitive signs of danger, they argue for taking a proactive approach—developing mitigation strategies early, even before we fully understand the risks.
Here’s a breakdown of the paper’s main ideas and what they mean for the future of AI.
The “Evidence Dilemma” and Why We Can’t Wait
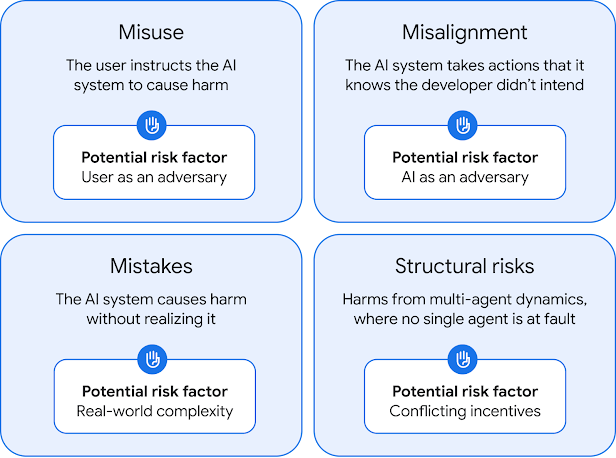
The paper opens with a key challenge in AGI safety: the evidence dilemma. It’s difficult to prove when something might become dangerous, especially before it exists. But waiting for certainty could be too late. DeepMind proposes preparing in advance, especially around what they call Exceptional AGI—systems performing better than 99% of humans in many non-physical tasks, like reasoning or planning.
They’re focused on current models built with gradient descent—like large language models—and setting aside more speculative superintelligence risks for now.
The Core of DeepMind’s AGI Safety Framework
Rather than one silver bullet, DeepMind’s approach rests on multiple technical pillars working together to reduce harm.
1. Safety Training
The goal is to teach AI models to behave well across different scenarios—not just via reward signals, but also by using tools like constitutional AI and language-based feedback systems.
2. Capability Suppression
Sometimes, the best way to prevent misuse is to avoid giving a model certain capabilities at all. Though it’s still debated how effective “unlearning” truly is, limiting access to dangerous skills is seen as a practical step for now.
3. Access Restrictions
Who gets to use advanced AI models—and how—matters. Security protocols, access control systems, and review processes all play a role in keeping dangerous tools out of the wrong hands.
4. Evaluation
Before deploying a model, you need to know what it’s capable of. This includes evaluating dangerous capabilities and using red teaming to poke holes in defenses and spot vulnerabilities.
5. Monitoring
Once AI systems are live, they need to be watched closely. Monitoring for misuse involves balancing detection with user privacy, using inputs like user prompts and interaction history to catch potential threats.
6. Security
Protecting the model’s internal “weights” (what it has learned) is a top priority. If someone gains access, they might extract dangerous capabilities or repurpose the model maliciously.
7. Deployment Safeguards
At launch, system-level protections can help limit risks—like built-in guardrails, user constraints, or escalation protocols when suspicious activity is detected.
Tackling the Harder Problem: Misalignment
Even if no one misuses AGI, it could still pose risks if its actions don’t align with human goals. DeepMind outlines several promising research directions for this:
– Amplified Oversight
Because humans can’t always oversee super-intelligent systems directly, techniques like debate, iterated amplification, and recursive reward modeling allow weaker humans to supervise stronger AIs through layered feedback systems. Among these, DeepMind is especially focused on debate.
– Guiding Model Behavior
Once you have a strong feedback signal, it needs to be applied effectively. Methods like process-based supervision (judging how an answer was reached, not just the outcome) and denser feedback modalities help models learn better.
– Myopic Training
One risk is that AI learns to “game the system” by optimizing for reward signals in unintended ways. Using approval feedback—rewarding good reasoning, not just good results—might prevent this.
– Externalized Reasoning
Getting AI models to show their work (like writing out steps in their thinking) helps humans understand and oversee them. This is where techniques like chain-of-thought prompting and training “thinking models” come into play.
– Interpretability
The more we understand how a model works internally, the easier it is to ensure safety. DeepMind is focusing on post-hoc methods—analyzing models after training to uncover hidden patterns, concepts, or algorithms. Tools like circuit analysis and probing are part of this toolkit, often guided by the Linear Representation Hypothesis (LRH), which assumes concepts can be mapped to directions in activation space.
Making the Case for Safety
Before releasing advanced models, DeepMind proposes building safety cases—structured arguments backed by evidence to show a model is safe.
There are two types:
- Inability Safety Case: The model just isn’t capable of causing serious harm.
- Control Safety Case: Risky capabilities exist, but they’re effectively controlled through mitigations.
They also mention future directions, like potentially verifying model behavior mathematically—though that’s still out of reach today.
Governance Still Matters
While this paper is heavy on technical detail, DeepMind makes it clear: tech alone isn’t enough. Global standards, transparency, and cooperation among developers are essential to prevent competitive pressures from eroding safety practices. Structural and policy-level risks will need their own solutions beyond what’s outlined here.
Final Thoughts
This paper isn’t a checklist—it’s a research roadmap. Many of the tools and techniques mentioned are still in development or unproven. But the message is clear: the time to act is now.
Google DeepMind’s approach gives the broader research and policy community a starting point to think seriously about AGI safety—before it’s too late to do so.
Main Takeaways:
- Start before there’s proof. Waiting until risks materialize is too late.
- Layered safety is key. There’s no single fix—training, suppression, monitoring, and oversight must work together.
- Human alignment is complex. Solving misuse is one thing; solving goal divergence is much harder.
- Interpretability can unlock trust. We need to understand what our models know and how they reason.
- Collaboration matters. No one organization can solve AGI safety alone.

